"Livet som..." är en bloggserie där vi får träffa olika personer i deras vardag och lära oss mer om deras yrkesroll.
Läs även avsnittet om hur det är att arbeta som ledande aktör inom 5G samt när Paulina Raymond presenterar hur det är att vara UX-designer.
I denna del av "Livet som" träffar vi Johan Sjögren som arbetar som maskininlärningskonsult på Neodev.
Johan har arbetat som maskininlärningskonsult de senaste tre åren, innan det arbetade han som Research Engineer och Accelerator Operator. Johan har en master i fysik från Lunds universitet och en PhD i kärnfysik från Glasgow University. För tillfället arbetar Johan som Data Scientist på IKEA.

Johan ska berätta mer om vad det innebär att arbeta som maskininlärningskonsult.
Hur maskininlärning och artificiell intelligens kan skapa värde

Vi börjar från början, i kärnan av allting och hoppar direkt in i den viktigaste frågan: "Hur skapar ML och AI värde?" Om ett företag ska använda ML/AI till något, är det för att skapa ett värde för företaget. Värde kan vara olika för olika bolag. Till exempel är värde för ett vinstdrivande bolag helt enkelt vinst, för en myndighet är det kanske inte vinst på samma sätt, i en ideell organisation är värde något annat. Det är ändå samma frågeställning som kan användas där och svaret är relativt enkelt: Fatta beslut och bättre beslut. Att fatta beslut kan kopplas till automatisering, dvs datasystem som fattar beslut automatiskt. Det kan också ha att göra med att man kan klona en expert. Om ett företag vill expandera sin affärsidé, kan det ibland vara lite som en flaskhals; det kräver att man har den mänskliga expertisen tillgänglig. Dock är ett datasystem mycket enklare att kopiera än en person med 10-20 års erfarenhet. Den andra delen är att bidra till att bättre beslut fattas. Detta görs med hänsyn till den samlade expertisen och sammanfoga det. Det kan även ha att göra med att använda komplex data. Människor är väldigt bra på att hantera vissa typer av komplex data men har svårt för exempelvis långa, svåra tabeller och statistik, eftersom vi människor inte har någon typisk intuition för det. Med hjälp av maskininlärning kan man fatta bättre beslut.
Ett exempel på hur det kan tillföra värde kan illustreras med en artikel som publicerades i tidningen Forskning & Framsteg från förra året. Artikeln handlar om en maskininlärningslösning där bilder på leverfläckar på huden analyseras för att klassificera huruvida de har hudcancer eller inte. Denna lösning var mycket bättre än någon läkare. Detta är ett exempel på att det faktiskt går att fatta ett automatiskt beslut utifrån en bild som faktiskt är bättre. Det är även ett bra exempel på hur man skapar värde genom att sätta bättre, snabbare diagnoser hos patienter; något som antagligen är uppskattat hos både patienter och läkare.
Vad är egentligen maskininlärning (ML)?
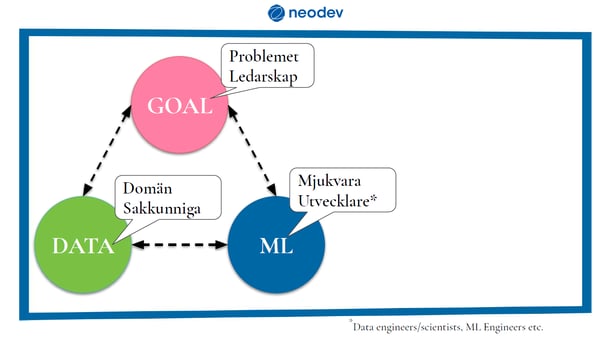
Det flyger runt lite olika termer, lite olika koncept, och det kan vara svårt utifrån, för de som inte har den tekniska bakgrunden, att se hur allt faktiskt hänger ihop. Då är det viktigt att skapa förståelse för maskininlärning tidigt i ett projekt för att kravställare och konsult ska sätta upp rätt förutsättningar.
Det första jag brukar göra är att bryta ner hur maskininlärning passar in i en organisation, genom att skapa en enkel bild som bilden på triangeln som finns ovan. Triangeln är mest till för att synliggöra ens tankar och idéer kring maskininlärning snarare än att det är en rigid struktur. Den här bilden är ett sätt att klassificera problem, möjligheter eller det som behövs arbetas med. De olika delarna i triangeln har jag valt att kalla för Goal, Data och ML. Det som kallas goal (mål) är problemet som behöver lösas, men det är även ledarskapsdelen, dvs vad det är vi vill uppnå, vilken vision vi har osv. ML-delen är det som primärt kännetecknas av mjukvara och utvecklare. Till sist har vi datadelen, som också kan kallas för expertdelen där även domän eller sakkunniga kan ingå.
Ja, men vad är då maskininlärning? Maskininlärning kan delas upp i lite olika kategorier och här näst tar jag upp fyra vanliga varianter.
Supervised learning

Den första delen kallas för supervised learning eller på svenska övervakad inlärning. Ett vanligt exempel på övervakad inlärning är klassifikation.
För att förklara klassifikation har jag ett exempel med en bild på ett lodjur. Frågan som ska ställas är: ”Vad är det för djur på bilden?” Rätt svar är att det är ett lodjur. För att få vår modell att lära sig det här, behöver vi dels bilden, dels ett rätt svar att associera med bilden. I det här fallet ett lodjur. Det är därför denna del kallas övervakad inlärning eftersom det alltid finns ett rätt svar. Det finns såklart fallgropar med övervakad inlärning. En fråga relaterat till detta skulle kunna vara: ”Är det en katt på bilden?” Ja, det beror på vad du menar. Det är ett kattdjur men det är ingen huskatt, det är ett lodjur. Här är det faktum som belyser att det faktiskt är övervakad inlärning. Beroende på vad för målbild som läggs in, dvs vad vi vill ska ske, kommer vår modell att lära sig utifrån detta. Katten var ett oskyldigt exempel, det kan såklart ha allvarliga konsekvenser om man ger ens modell fundamentalt fel målbild.
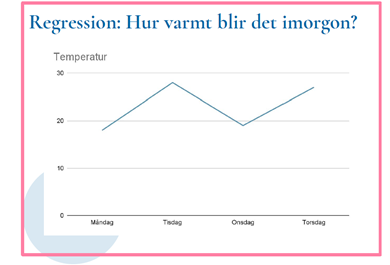
Det andra exemplet på övervakad inlärning är regression. Regression används i de fall där man vill ha en variabel i stället för en klass, som i exemplet ovan. Ett typiskt exempel kopplat till regression, är vädret och frågan hur varmt det kommer bli imorgon. Detta är en ganska svår regression att arbeta med, något som flera väderappar har visat.
Unsupervised learning
Nästa del är unsupervised learning eller oövervakad inlärning på svenska. Detta går ut på att strukturen hos datan är det viktiga och det som faktiskt ska läras in. Ett exempel på detta är att den underliggande sannolikhetsfördelningen på den data som finns är det som ska läras in. Den stora skillnaden mellan oövervakad inlärning och övervakad inlärning är att i övervakad finns det ett rätt svar. Det innebär att om du till exempel skulle ha 10 000 bilder, måste du gå igenom varenda bild och berätta vad som är rätt svar för varje bild. Det kan vara tidsödande.
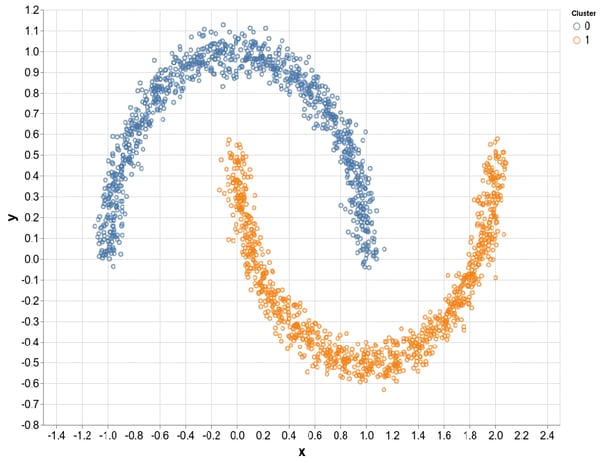
I oövervakad inlärning behöver endast strukturen läras in utan någon relevans till något rätt svar. Oövervakad inlärning kan därför ses som en genväg och kan innebära att man snubblar på en struktur som stämmer överens med det som eftersöks. Men det handlar nästan bara om tur. Ett exempel på oövervakad inlärning kan vara att du till exempel vill klassificera varje bilmärke som dyker upp i en bild. Sannolikheten är då större att det som klassificeras tillhör något annat än den struktur som man faktiskt letar efter.
Reinforcement learning
Den tredje delen heter reinforcement learning eller förstärkningsinlärning på svenska. Den här delen lär sig genom interaktion. Till en början är AI:n inte särskilt bra men efter en tids interaktion, blir den betydligt bättre. Reinforcement learning används en hel del i olika spelmiljöer.
Semi-supervised learning
Den fjärde delen heter semi-supervised learning eller semi-övervakad inlärning på svenska. Den här delen lär sig delvis från annoterad data (som i övervakad inlärning) och delvis med hjälp av strukturer från oövervakad inlärning. Ett exempel kopplat till detta var när Panama-dokumenten släpptes år 2016. Det var miljontals dokument som skulle varit omöjligt för en journalist att gå igenom. I stället för att gå igenom varje dokument, togs ett antal dokument och märktes upp, cirka 100 av dem. Efter detta utfördes dels övervakad, dels oövervakad inlärning på dessa dokument. Sedan kördes en ny uppsättning av dokumenten igenom och då granskades det hur bra det hade blivit baserat på det som redan hade annoterats. Om det inte var inte tillräckligt bra, användes nya dokument i träningsgruppen och så fortsatte det tills man var nöjd med träffsäkerheten man fick ut. Detta arbetssätt skapade ett ganska bra filter för att få ut intressanta dokument utan att alla miljoner dokument behövde gås igenom.
Förutom dessa fyra olika delar, ingår även sökalgoritmer, planeringsalgoritmer och optimeringsalgoritmer när man pratar om vad som ingår i AI-fältet förutom ML. Något som är viktigt att inse när det kommer till risker med ML, är att de inte bara försvinner för att man använder AI i stället. Alla problem man stöter på kan därför inte lösas bara för att man byter fält
Vad innebär det att vara maskininlärningskonsult?
Vad är det för kompetenser som behövs? Man behöver kunna maskininlärning. Och vad innebär det? Det är dels kunskap inom diverse olika mjukvarubibliotek, det innebär också en viss kunskap inom statistik, matematisk modellering och andra besläktade områden. ML-Ops, är något som har tillkommit på senare år. Det är för att man inom ML också behöver kompetenser för att kunna leverera lösningarna ut till en verksamhet på ett tillförlitligt sätt. Det måste fungera integrerat i verksamheten och det ställer lite andra krav än att bara kunna ta fram algoritmerna. Detta är det som kallas ML-Ops.
AI/ML utmaningar: implementering och etik
Kopplingen mellan Mål och ML (triangeln nämnd tidigare) karaktäriseras mycket av okunskap. Det kanske inte är så konstigt, eftersom många tänker ”jag kan inte så mycket om ML”, men det är faktiskt inte den okunskapen jag syftar på. Denna okunskap är snarare av typen: ”Vilka beslut fattas och varför fattas dessa beslut?” samt ”Vilka är våra uppsatta mål?”. Det har nödvändigtvis inte något med ML att göra, utan det är kunskap om hur organisationen fungerar, vilka mål som finns och hur väl olika beslut fungerar. Det är en del av ledarskapet och visionen, att veta hur bra besluten är och hur man mäter dem och kanske också hur mycket det är värt att fatta bättre beslut. Till slut kommer detta behöva översättas till någonting som kan tolkas av en dator eller en ML-algoritm. Först i det steget behövs lite mer kunskap om ML för att kunna svara på och hitta lösningar kring dessa mål och frågeställningar.
En annan vanlig utmaning vid implementering av AI/ML kan lite krasst kallas ovilja, i vissa fall bra/motiverad ovilja men många fall dålig ovilja. Lösningen, från Fof artikeln, som analyserar leverfläckar kan ses som en typ av ovilja. Varför finns det inte en applikation för detta eller varför används det inte på vårdcentraler osv. För mig veterligen gör det ju inte det. Vi kan börja med de sämre ursäkterna kopplat till ovilja. En ursäkt kan vara att bilderna på leverfläckarna var för tillrättalagda eller att bilderna var för välcentrerade och i bra ljus. Det kan krocka med uppfattningen att läkare kanske tittar på dem i lite sämre ljus och i en annan vinkel. Detta var en av de sämre ursäkterna som framfördes i artikeln och ett tydligt exempel på dålig ovilja.
Om vi tar ett exempel på bra ovilja, då är det viktigt att fundera på vad som är målet och om man är nöjd med det målet. En läkare som gör ett allvarligt misstag kan i slutändan förlora sin legitimation. Men vad händer om ett misstag i stället begås av en AI? Detta är en frågeställning som är aktuell i många andra områden, där ansvar och etik spelar viktiga roller. Man kan då ställa sig frågorna: ”Är det etiskt rätt att låta bli att använda något som är bättre än det som används för tillfället för att det inte går att hålla någon ansvarig på samma sätt som med en människa?” Det är då viktigt att fundera på vad det är för mål man vill uppnå och vad som är det viktigaste. Är det viktigaste att det finns bästa möjliga vård eller är det viktigaste att man legalt har knutit upp hur någon kan hållas ansvarig inom vården? Är det verkligen rimligt att göra på detta vis, vad händer om vi börjar använda AI på detta sätt, får det någon oväntad konsekvens i sådana fall? Det är en viktig diskussion att ha och en viktig del inom ovilja.
Ovilja kan också till exempel komma från en rädsla att bli ersatt av det här systemet på arbetet. Då är det viktigt att återkomma till frågeställningen gällande vad man har för mål. Är målet att ersätta personer eller att förstärka dem? Detta kan såklart leda till relativt svåra diskussioner i slutändan. Vad gör vi när vi inte behöver ha folk till så många olika saker längre, många arbetstillfällen kanske försvinner. Å andra sidan kan resultatet leda till att de anställda får mer tid till att göra andra viktigare och mer värdefulla uppgifter.
När det gäller andra etiska frågor kring AI/ML så är det ett område det jobba mycket på och till exempel är standardiseringsorgan och standarder för maskininlärning ett område man har börjat jobba mer på. Framför allt baserat på hur data har använts av vissa organisationer. Där tycker jag att det snarare är affärsidén som man borde ifrågasätta, snarare än vd algoritmen faktiskt gör. En annan fråga är det här med människa kontra automation. Ta till exempel det franska flygplanet som kraschade över Atlanten, Air France Flight 447 år 2009.
Där visar rapporter att autopiloten p.g.a. ett tillfälligt fel kopplades ur. Om de hade väntat i ca 20 sekunder och sedan satt på autopiloten igen, hade planet inte behövt krascha. De kraschade för att de började göra fel saker. Vi accepterar att människor gör misstag men vi ska ersätta det med en AI som är perfekt? Räcker det inte med att AI bara är bättre än människan? Perfect is the enemy of good som man brukar säga. Det är kanske inte så roligt i och för sig att veta att man sitter i ett AI-drivet flygplan som man vet bara ska vara ”bättre än en människa”.
Största fallgropen inom ML/AI
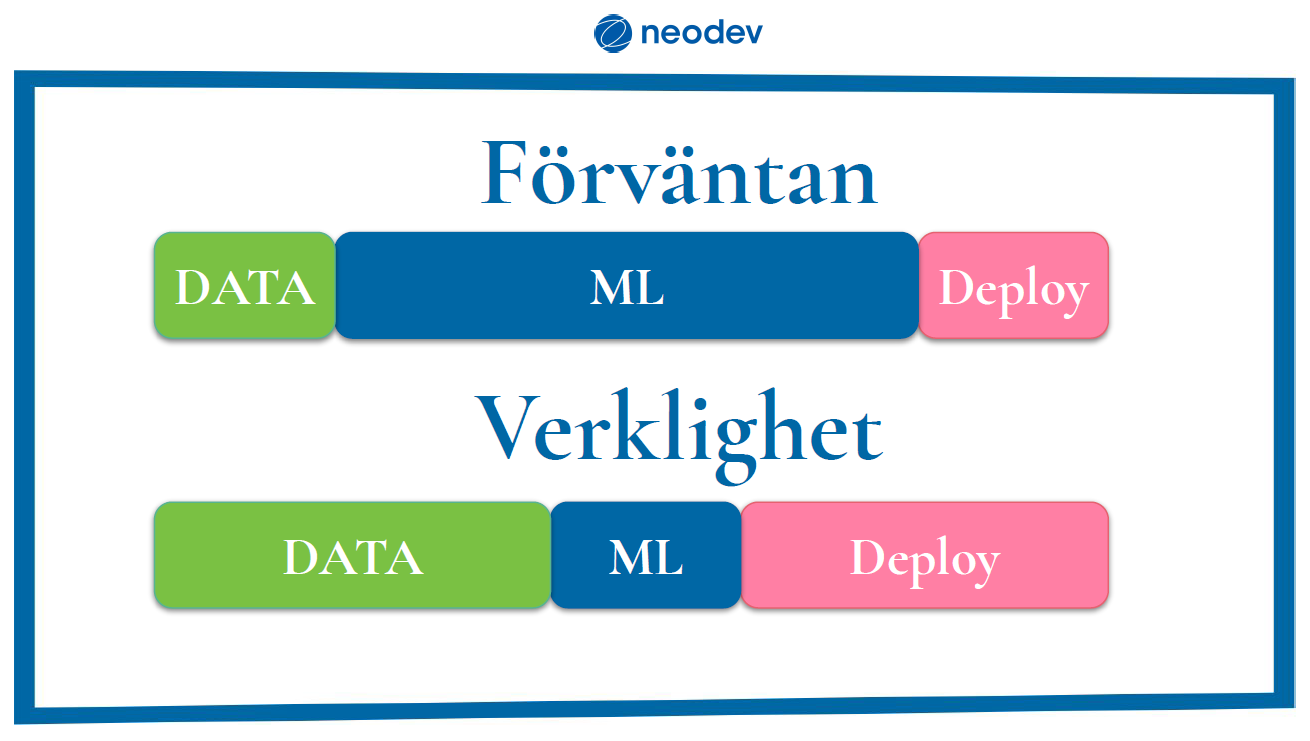
Vad är egentligen den största fallgropen när det gäller ML och AI? Denna fallgrop kan uppstå när man ställer sig frågan: ”Hur kan vi använda ML/AI (nu)?” Man vill alltså så fort som möjligt börja använda sig av AI/ML. Detta är ofta kopplat till en orealistisk bild av hur det faktiskt ser ut. Många tänker sig att det är ML-delen som är mest resurs- och tidskrävande och att data-delen dvs själva delen att få ut den till verksamheten, att man deployar, inte tar någon tid alls. I verkligheten är ML-delen en väldigt liten del och det är data-delen och att deploya som tar tid.

Så i stället för att använda den här frågeställningen: ”hur kan du använda ML/AI (nu)?” bör man i stället fråga sig själv: ”vad behöver du göra nu, för att använda ML/AI sen?” Det hänger ihop med något en karateinstruktör en gång sa till mig. På frågan: ”vilken är den viktigaste tekniken?” Svarade han: ”nästa teknik”. Så fort du är färdig med det viktigaste så är nästa fråga vad gör du härnäst. Det tog Google många år att ersätta sin sökmotor med en ML-baserad algoritm. Google hann finnas i över tio år innan de lyckades med det. Det kan alltså ta lite tid innan man kommer dit man vill vara.
Nya användningsområden för AI och ML
Jag tror att det finns flera områden som hade kunnat ha stor nytta av ML, till exempel tillverkningsindustrin. För mig veterligen är det ett område där det inte används speciellt mycket i dagsläget. Ett användningsområde som jag ser potential inom är när det kommer till svinn. Svinn kan undvikas genom att veta om en komponent är undermålig eller inte. Såklart förekommer det tester vid produktionstillfället, men det kan vara svårt att koppla ihop hela kedjan. Man tillverkar en komponent på en plats och sedan ska denna komponent användas tillsammans med andra komponenter på en annan plats. Det kan vara så att det finns ett litet fel men att produkten ändå kan funka felfritt förutsatt att den hamnar med andra icke-felaktiga komponenter. Hamnar den smått felaktiga komponenten med andra felaktiga komponenter så blir det en felaktig produkt som inte kommer att fungera. Inom detta område tror jag det hade fungerat bra att inkorporera en ML-modell, och samtidigt då undvika svinn eftersom man då vet vilka komponenter som kan kombineras ihop eller att man från början inte skickar ut produkten överhuvudtaget.
Hur hittar jag uppdrag som maskininlärningskonsult?
A Society är den nya tidens konsultbolag och kan hjälpa till att förmedla kontakter mellan konsulter och kunder som söker efter konsulter inom maskininlärning och artificiell intelligens. Registrera dig på hemsidan så får du en personlig kontaktperson som kontaktar dig för att höra vad du letar efter för typ av uppdrag samt så får du tillgång till andra uppdrag som vi annonserar ut i vårt nätverk. Att gå med i vårt nätverk är helt kostnadsfritt. Lycka till med ditt nästa uppdrag!
